
CSDN:https://blog.csdn.net/weixin_44576836/article/details/140526575
源码地址:https://github.com/saikaisa/Multicycle_CPU
一、实验任务
实验目的
- 在单周期 CPU 实验完成的前提下,理解多周期的概念。
- 熟悉并掌握多周期 CPU 的原理和设计。
- 进一步提升运用 Verilog 语言进行电路设计的能力。
实验任务
本次设计是对单周期 CPU 实验的拔高,前期的实验准备同单周期 CPU 的实验,在单周期 CPU 中只要求实现了五条指令,但此处要求扩展到 25 条以上指令,且必须包括四大类型:传送、运算、访存、控制转移。
实验设备
- Windows 11
- Vivado 2022.2
- Python 运行环境
二、实验设计
CPU设计
1. 实现的指令
一共实现了25条指令,包括 R, I, J 三大类型指令,以及 halt(停机)指令。
R 型指令
R 型指令都属于运算指令(加减法、逻辑运算、移位运算、比较运算),都有写回(WB)阶段。
- add, addu 和 sub, subu 虽然分别为有符号和无符号的加减法,但是它们硬件上的运算逻辑都是相同的(相同的补码运算),只是有符号加法会判断是否溢出,无符号不会判断溢出,并且最后对结果的解释(带符号位或不带符号位)不同。本设计为简化 CPU 结构,没有设计判断溢出的电路,也不需要对结果进行解释处理,故有符号和无符号的运算实现是相同的,只是指令功能码不同。
- 左/右移位运算指令 (sll, srl) 的移位量 sa 都是无符号数。
- 比较指令 (slt) 将 rs, rt 的比较结果存储在 rd 中,若 rs < rt 则将 rd 寄存器的值置 1,反之置 0。
I 型指令
I 型指令的运算指令(addiu, andi, ori, xori, slti)与 R 型指令类似,只是其中一个源操作数变成了立即数。
- sw/lw 指令是仅有的两条有访存(MEM)阶段的指令,但 sw 没有写回阶段而 lw 有,sw 需要 4 个时钟周期,lw 需要 5 个时钟周期。
- 分支跳转指令(beq, bne, bltz)用到了 ALU 的两个信号 zero 和 sign,它们的实现如下:
- beq, bne:将 rs 寄存器的值与 rt 寄存器的值相减,如果等于 0 则说明 rs = rt,ALU 产生信号 zero = 1,反之不等则为 0。控制单元根据 zero 产生相应的控制信号。
- bltz:将 rs 寄存器的值与 0 号寄存器的值(始终为 0)相加,得到的结果 result 仍为 rs 的值,但此时 ALU 根据结果产生信号 sign,若 rs < 0 则 result < 0,此时信号 sign = 1,反之 sign = 0。控制单元根据 sign 产生相应的控制信号。
J 型指令
J 型指令是地址跳转指令,它会通过修改当前 PC 的值来决定 CPU 将要执行的下一条指令。详见指令功能表。
$31 寄存器的作用
在本设计中,$31寄存器被 jal 指令所用,它存储了返回地址( jal 指令的下一条指令的地址),在 jal 指令跳转到其他代码段后,如果想要返回,可以使用 j $31 指令回到原代码段。
地址跳转说明
{pc[31:28](PC值高4位),target,2'b00} 是指令实际表示的地址。
例如 jal 0x00000050 中,目标地址是 0x00000050(32b'1010000)
经过汇编器处理,0x00000050 去掉了低2位(指令地址的低2位一定始终为0)和高4位,存储在指令的二进制编码中,二进制编码是 011110(op[31:26]) 000000000000000000010100(target[25:0])
最后指令在CPU中通过 `{currentPCAddr[31:28](还原高4位), target[25:0], 2'b00(还原低2位)}` 拼接,得到实际的目标地址。
指令功能表
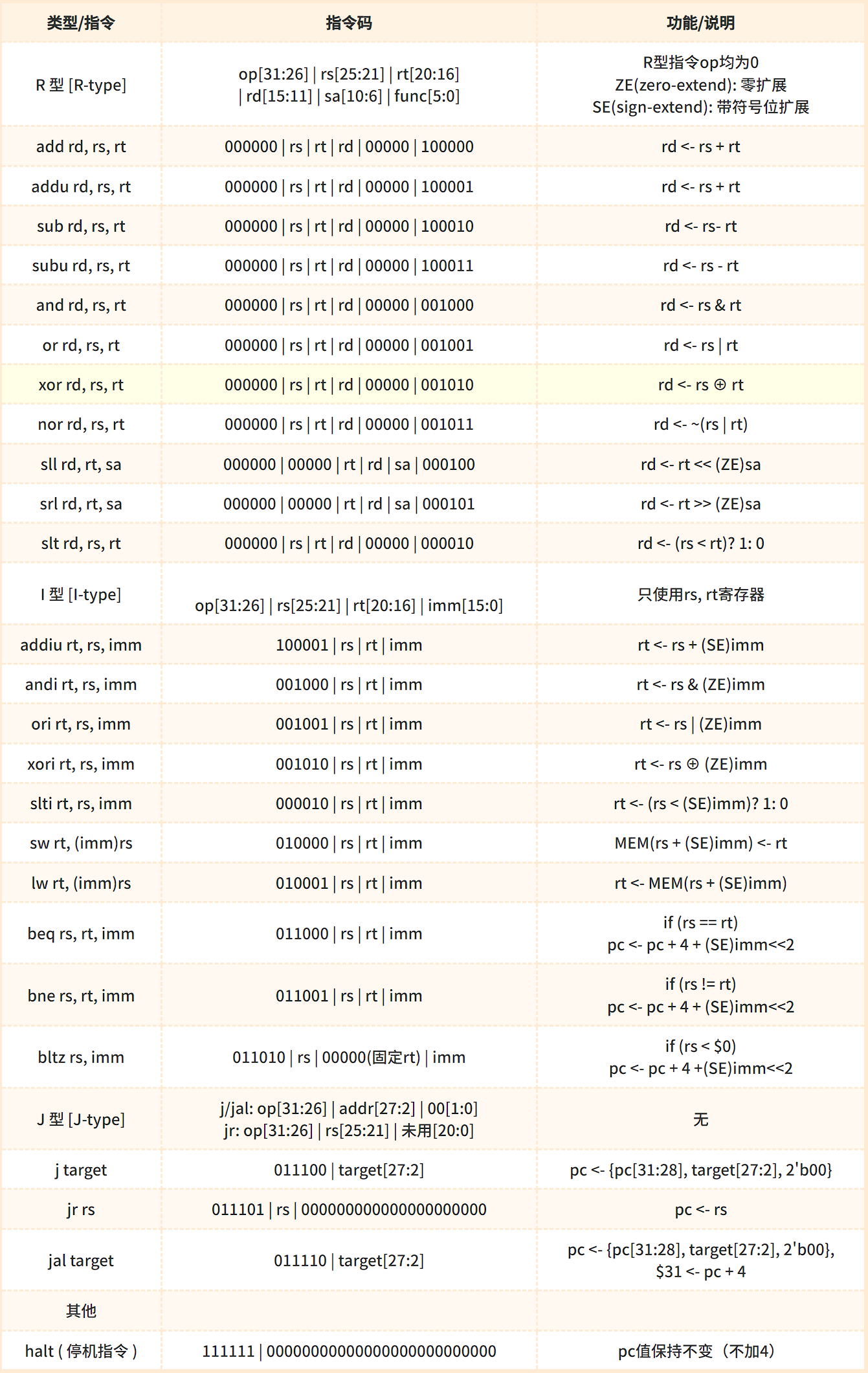
2. CPU整体设计框图
图中,深蓝色字体的信号为控制信号,详见“4. 控制信号功能表”;淡蓝色字体为阶段隔离寄存器中的信号转换,可以在“试验实施——1. Verilog 代码——阶段隔离寄存器”中找到有关内容。

3. 状态机
每个时钟周期,状态机(ControlFSM)都会根据当前正在执行的指令的操作码(op)或功能码(func)来决定接下来切换到哪一个状态。
- 闲置(IDLE)只有在 reset = 0 时才有效,实际上它没有被明确定义
- 取指(FETCH)只有 1 个可能的状态
- 译码(DECODE)只有 1 个可能的状态
- 执行(EXE)有 3 个可能的状态
- 访存(MEM)只有 1 个可能的状态
- 写回(WB)有 2 个可能的状态

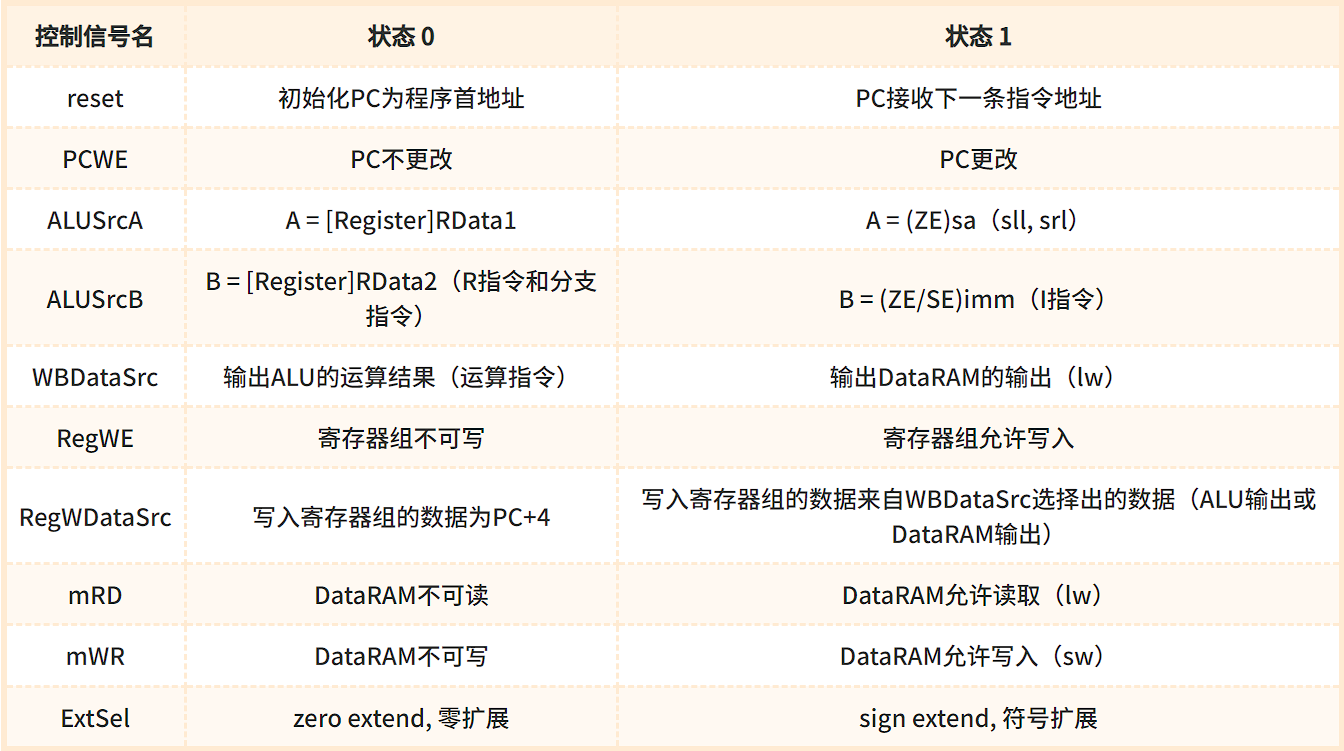
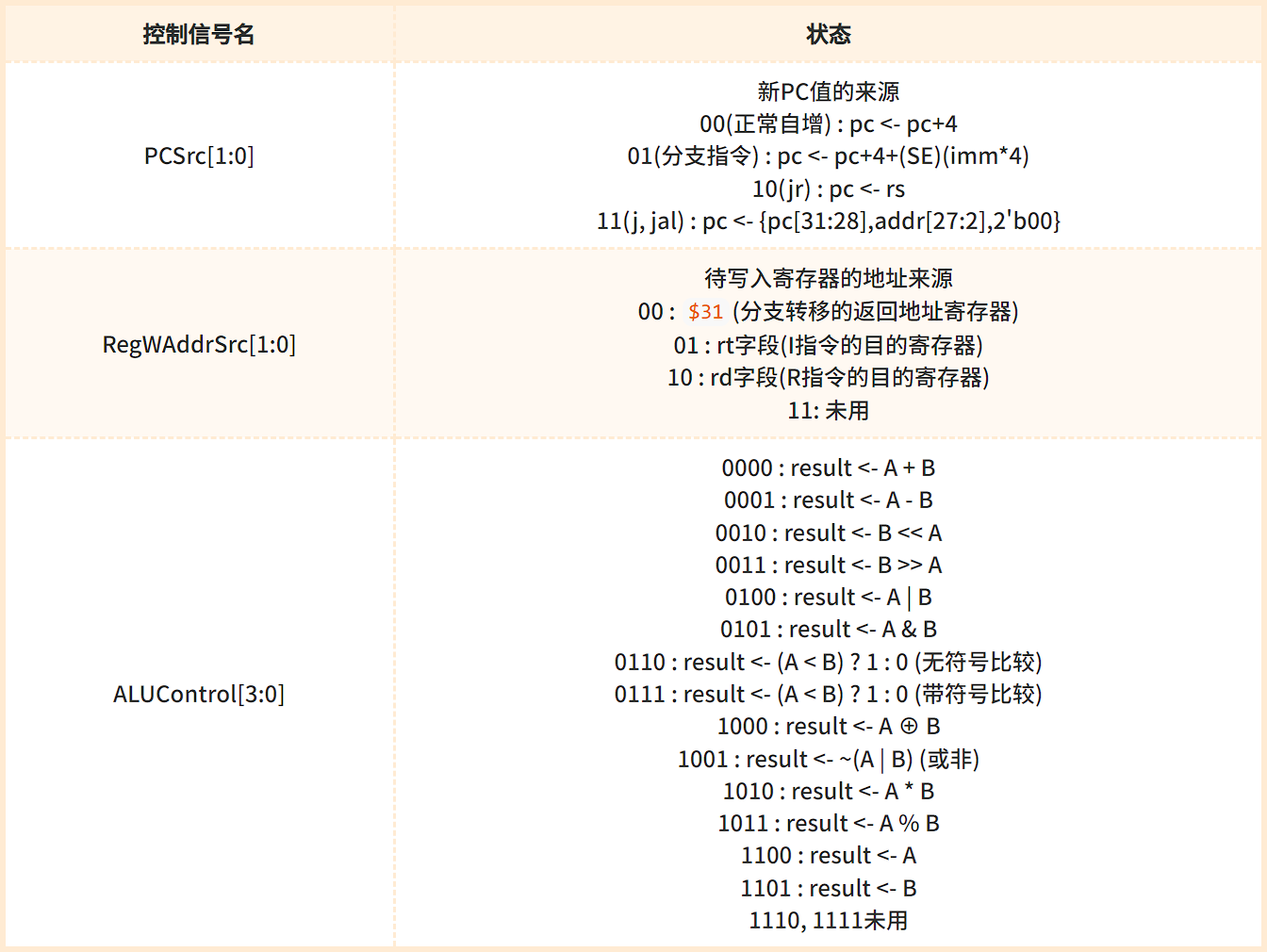
4. 控制信号功能表
控制单元(ControlUnit)是 CPU 的核心,它根据当前正在执行的指令,产生各种控制信号。指令与控制信号的对应关系见“5. 指令与控制信号的对应关系”。
控制信号的功能见下表:
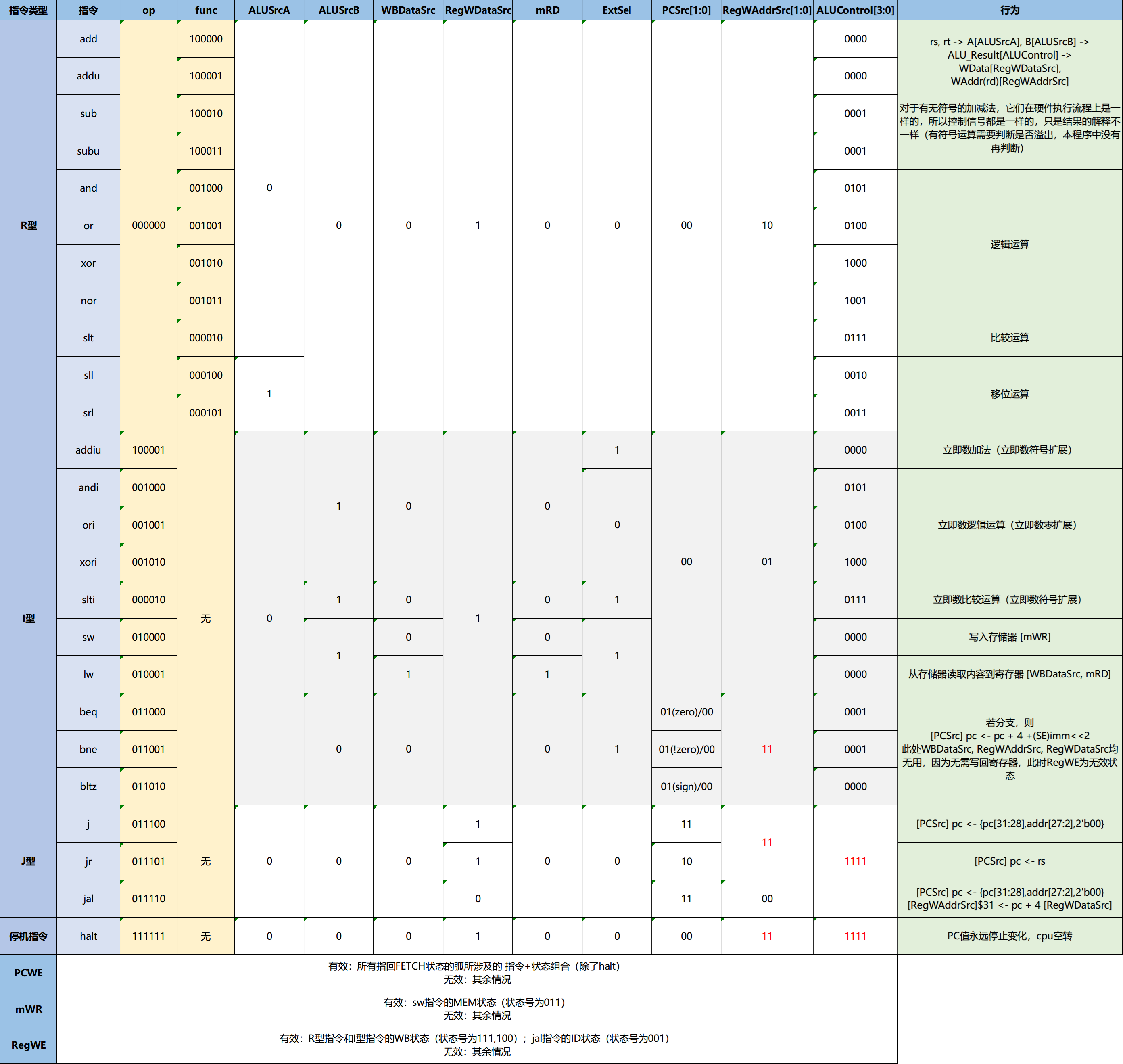
5. 指令与控制信号的对应关系
PCWE, mWR, RegWE 不仅与正在执行的指令有关,还与当前时钟周期所处的状态有关,而除这三个控制信号之外的其他控制信号则与当前状态无关,故将它们分为两组讨论。
实验实施
1. Verilog 代码
头文件
define.v
这里为了增强代码的可读性,并避免编写代码时出现混乱,对一些固定的二进制数值进行了宏定义。
ALUControl:ALU 控制信号state:状态机的各种状态op,func: 指令的操作码和功能码
该文件内容较为重复,详见源码。
顶层模块
MulticycleCPU.v
这是CPU的顶层模块,调用所有子模块进行处理。
module MulticycleCPU(
input clk,
input reset,
output [2:0] state, // 状态机状态
output [31:0] currentPCAddr, nextPCAddr, // 当前PC地址,下一PC地址
output [31:0] IF_instrution, // 指令
output [5:0] op,
output [5:0] func,
output [4:0] rs, rt, rd, // 寄存器地址,rt,rd和$31竞争RegWAddr
output [4:0] shamt, // 移位量,与ID_RegRData1竞争ALU_A
output [15:0] imm, // 立即数,与ID_RegRData2竞争ALU_B
output [25:0] target,
output [31:0] ID_RegRData1, ID_RegRData2, // 寄存器数据
output [31:0] ALU_A, ALU_B, // ALU输入
output [31:0] EX_ALU_result, // ALU结果
output [31:0] MEM_RAMDataOut, // 存储器数据输出,与EX_ALU_result和PC+4竞争RegWData
output [4:0] RegWAddr, // 写回寄存器地址
output [31:0] RegWData // 写回寄存器数据
);
/* 部分数据通路 - 锁存 */
wire [31:0] ID_instrution; // ID_instrution(下降沿)比IF_instrution(上升沿)晚半个时钟周期产生
wire [31:0] EX_RegRData1, EX_RegRData2;
wire [31:0] MEM_ALU_result, MEM_WBData;
wire [31:0] WB_WBData;
/* 部分数据通路 - 其他 */
wire ALU_zero, ALU_sign; // ALU标志位
wire [31:0] extended_shamt, extended_imm;
wire [25:0] target;
/* 控制信号 */
wire PCWE, ALUSrcA, ALUSrcB, WBDataSrc, RegWE, RegWDataSrc, mRD, mWR, ExtSel;
wire [1:0] PCSrc;
wire [1:0] RegWAddrSrc;
wire [3:0] ALUControl;
/* 分支指令和跳转指令形成的目标地址 */
wire [31:0] branchTarget;
wire [31:0] jumpTarget;
assign branchTarget = currentPCAddr + 4 + (extended_imm<<2);
assign jumpTarget = {currentPCAddr[31:28], target, 2'b00};
/* 实例化以下模块:
ControlFSM, ControlUnit (控制部件)
PC, InstructionROM, RegisterFile, ALU, DataRAM (主要模块)
IR, DECODE_EXE, EXE_MEM, MEM_WB (阶段隔离寄存器,基于IR和D触发器)
EXT5T32, EXT16T32 (位数扩展器)
Mux_nextPCAddr, Mux_RegWAddr, Mux_RegWData, Mux_ALU_A, Mux_ALU_B, Mux_WBData (多路选择器)
*/
// ...
endmodule
控制部件
ControlFSM.v
这是有限状态机,通过状态机通知CPU当前指令处于什么阶段。
module ControlFSM(
input clk, reset,
input [5:0] op,
input [5:0] func,
output reg PCWE,
output reg [2:0] state
);
/* 时钟上升沿改变状态 */
always @(posedge clk or negedge reset) begin
if(reset == 0) begin
state <= `FETCH;
PCWE <= 1;
end
else begin
/*
======= FSM state transition =======
FETCH->DECODE: ALL
DECODE->FETCH: j,jr,jal,halt
DECODE->EXE1: sw,lw
DECODE->EXE2: beq,bne,bltz
DECODE->EXE3: add,addu,addiu,sub,subu,and,andi,or,ori,xor,xori,nor,sll,srl,slt,slti
EXE1->MEM: sw,lw
EXE2->FETCH: beq,bne,bltz
EXE3->WB2: add,addu,addiu,sub,subu,and,andi,or,ori,xor,xori,nor,sll,srl,slt,slti
MEM->FETCH: sw
MEM->WB1: lw
WB1->FETCH: lw
WB2->FETCH: add,addu,addiu,sub,subu,and,andi,or,ori,xor,xori,nor,sll,srl,slt,slti
*/
case(state)
`FETCH: state <= `DECODE;
`DECODE: begin
if(op==`J || op==`JR || op==`JAL || op==`HALT) state <= `FETCH;
else if(op==`SW || op==`LW) state <= `EXE1;
else if(op==`BEQ || op==`BNE || op==`BLTZ) state <= `EXE2;
else state <= `EXE3; // R-type and I-type operational instructions
end
`EXE1: state <= `MEM;
`EXE2: state <= `FETCH;
`EXE3: state <= `WB2;
`MEM: begin
if(op==`LW) state <= `WB1;
else state <= `FETCH; // sw
end
`WB1: state <= `FETCH;
`WB2: state <= `FETCH;
endcase
end
end
endmodule
ControlUnit.v
这是控制单元,产生各种CPU运作必需的控制信号。
`timescale 1ns / 1ps
`include "defines.v"
module ControlUnit(
input clk,
input zero, sign,
input [2:0] state,
input [5:0] op, func,
output reg PCWE, mWR, RegWE,
output reg ALUSrcA, ALUSrcB, WBDataSrc, RegWDataSrc, mRD, ExtSel,
output reg [1:0] PCSrc,
output reg [1:0] RegWAddrSrc,
output reg [3:0] ALUControl
);
reg [13:0] control; // {ALUSrcA, ALUSrcB, WBDataSrc, RegWDataSrc, mRD, ExtSel, PCSrc[1:0], RegWAddrSrc[1:0], ALUControl[3:0]}
reg [2:0] wr_control; // {PCWE, mWR, RegWE}
/* 产生控制信号,实际上每个时钟上下沿都会触发 */
always @(negedge clk or state or op or func or zero or sign) begin
/* 与状态无关的控制信号 */
// R-type
if(op == `R_TYPE) begin
case(func)
`ADD,`ADDU: control = 14'b000100_00_10_0000;
`SUB,`SUBU: control = 14'b000100_00_10_0001;
`AND: control = 14'b000100_00_10_0101;
`OR: control = 14'b000100_00_10_0100;
`XOR: control = 14'b000100_00_10_1000;
`NOR: control = 14'b000100_00_10_1001;
`SLT: control = 14'b000100_00_10_0111;
`SLL: control = 14'b100100_00_10_0010;
`SRL: control = 14'b100100_00_10_0011;
endcase
end
// I-type, J-type and halt
else begin
case(op)
`ADDIU: control = 14'b010101_00_01_0000;
`ANDI: control = 14'b010100_00_01_0101;
`ORI: control = 14'b010100_00_01_0100;
`XORI: control = 14'b010100_00_01_1000;
`SLTI: control = 14'b010101_00_01_0111;
`SW: control = 14'b010101_00_01_0000;
`LW: control = 14'b011111_00_01_0000;
`BEQ: control = (zero == 1) ? 14'b000101_01_11_0001 : 14'b000101_00_11_0001;
`BNE: control = (zero == 0) ? 14'b000101_01_11_0001 : 14'b000101_00_11_0001;
`BLTZ: control = (sign == 1) ? 14'b000101_01_11_0000 : 14'b000101_00_11_0000;
`J: control = 14'b000100_11_11_1111;
`JR: control = 14'b000100_10_11_1111;
`JAL: control = 14'b000000_11_00_1111;
`HALT: control = 14'b000100_00_11_1111;
endcase
end
{ALUSrcA, ALUSrcB, WBDataSrc, RegWDataSrc, mRD, ExtSel, PCSrc[1:0], RegWAddrSrc[1:0], ALUControl[3:0]} <= control[13:0];
/* 与状态有关的控制信号 */
case(state)
// 注:PCWE需要在下降沿的时候改变,因为上升沿是PC改变的时候,与PCWE同时改变可能不太稳定
`DECODE: wr_control = { (clk==0) ? ((op==`J||op==`JR||op==`JAL) ? 1'b1 : 1'b0) : PCWE,
1'b0,
(op==`JAL) ? 1'b1 : 1'b0
};
`MEM: wr_control = { (clk==0) ? ((op==`SW) ? 1'b1 : 1'b0) : PCWE,
(op==`SW) ? 1'b1 : 1'b0,
1'b0
};
`EXE2: wr_control = { (clk==0) ? 1'b1 : PCWE,
1'b0,
1'b0
};
`WB1,`WB2: wr_control = { (clk==0) ? 1'b1 : PCWE,
1'b0,
1'b1
};
default: wr_control = { (clk==0) ? 1'b0 : PCWE,
1'b0,
1'b0
};
endcase
{PCWE, mWR, RegWE} <= wr_control[2:0];
end
endmodule
主要模块
PC.v
module PC(
input clk,
input reset,
input WE,
input [31:0] nextPCAddr,
output reg [31:0] currentPCAddr
);
initial currentPCAddr <= 0;
always @(posedge clk or negedge reset) begin
if(reset == 0) currentPCAddr <= 0;
else begin
if(WE == 1) currentPCAddr <= nextPCAddr;
else currentPCAddr <= currentPCAddr;
end
end
endmodule
InstructionROM.v
由于 COE 文件加载方式是基于IP核的,我的课程设计只实现仿真,并没有打算使用IP核。但是我使用了类似的方式加载指令 ROM。
module InstructionROM(
input [31:0] addr,
output [31:0] instruction
);
// 256个存储单元的ROM,每个存储单元1个字节,一条指令占4个存储单元,最多存储64条指令
reg [7:0] ROM [0:255];
// 读取二进制代码文件,每行一条指令(32位),每8位用一个空格隔开,因为每次只能读取一个ROM存储单元(8位)
initial begin
$readmemb("D:/CodeProjects/vivado project/Multicycle_CPU/machine_code.txt", ROM);
end
assign instruction[31:24] = ROM[addr+0];
assign instruction[23:16] = ROM[addr+1];
assign instruction[15:8] = ROM[addr+2];
assign instruction[7:0] = ROM[addr+3];
endmodule
因为手动生成二进制机器码过于复杂,所以我编写了一个基于python简易汇编器,根据我的汇编指令格式转换成相应的二进制机器码。
汇编器: assembler.py
import os
import re
funct_codes = {
'add': '100000',
'addu': '100001',
'sub': '100010',
'subu': '100011',
'and': '001000',
'or': '001001',
'xor': '001010',
'nor': '001011',
'sll': '000100',
'srl': '000101',
'slt': '000010'
}
opcodes = {
'addiu': '100001',
'andi': '001000',
'ori': '001001',
'xori': '001010',
'slti': '000010',
'sw': '010000',
'lw': '010001',
'beq': '011000',
'bne': '011001',
'bltz': '011010',
'j': '011100',
'jr': '011101',
'jal': '011110',
'halt': '111111'
}
def register_to_bin(register):
return bin(int(register[1:]))[2:].zfill(5)
def immediate_to_bin(immediate):
return bin(int(immediate) & 0xFFFF)[2:].zfill(16)
def address_to_bin(address):
# 转换16进制地址为二进制,并去掉末尾两位
bin_address = bin(int(address, 16))[2:].zfill(28) # 转换为28位二进制
return bin_address[:-2].zfill(26) # 去掉末尾两位并填充为26位
def assemble_instruction(instruction):
parts = re.split(r'\s|,|\(|\)', instruction)
parts = [p for p in parts if p]
opcode = parts[0]
if opcode in funct_codes:
if opcode in ['sll', 'srl']:
rt = register_to_bin(parts[2])
rd = register_to_bin(parts[1])
sa = bin(int(parts[3]))[2:].zfill(5)
funct = funct_codes[opcode]
return f'000000{"00000"}{rt}{rd}{sa}{funct}'
else:
rs = register_to_bin(parts[2])
rt = register_to_bin(parts[3])
rd = register_to_bin(parts[1])
funct = funct_codes[opcode]
return f'000000{rs}{rt}{rd}{"00000"}{funct}'
elif opcode in opcodes:
op_bin = opcodes[opcode]
if opcode in ['j', 'jal']:
address = address_to_bin(parts[1])
return f'{op_bin}{address}'
elif opcode == 'jr':
rs = register_to_bin(parts[1])
return f'{op_bin}{rs}{"0" * 21}'
elif opcode in ['beq', 'bne', 'bltz']:
rs = register_to_bin(parts[1])
if opcode == 'bltz':
imm = immediate_to_bin(parts[2])
return f'{op_bin}{rs}{"00000"}{imm}'
rt = register_to_bin(parts[2])
imm = immediate_to_bin(parts[3])
return f'{op_bin}{rs}{rt}{imm}'
elif opcode in ['sw', 'lw']:
rt = register_to_bin(parts[1])
imm = immediate_to_bin(parts[2])
rs = register_to_bin(parts[3])
return f'{op_bin}{rs}{rt}{imm}'
elif opcode == 'halt':
return f'{op_bin}{"0" * 26}'
else:
rt = register_to_bin(parts[1])
rs = register_to_bin(parts[2])
imm = immediate_to_bin(parts[3])
return f'{op_bin}{rs}{rt}{imm}'
else:
raise ValueError(f"Syntax Error: {instruction}")
if __name__ == "__main__":
# 获取当前脚本所在的目录
script_dir = os.path.dirname(os.path.abspath(__file__))
# 拼接相对路径
assembly_path = os.path.join(script_dir, 'assembly_code.asm')
binary_path = os.path.join(script_dir, 'machine_code.txt')
# 打开文件,显式指定编码为UTF-8
with open(assembly_path, 'r', encoding='utf-8') as file:
assembly_code = file.readlines()
# 忽略注释
assembly_code = [
line.split('#')[0].strip()
for line in assembly_code
if line.strip() and not line.strip().startswith('#')
]
# 写入文件
with open(binary_path, 'w') as outfile:
for instruction in assembly_code:
binary_code = assemble_instruction(instruction)
formatted_binary_code = ' '.join([binary_code[i:i + 8] for i in range(0, 32, 8)])
outfile.write(f"{formatted_binary_code}\n")
print(f"{instruction} -> {binary_code}")
RegisterFile.v
寄存器堆。自由读;写入为时序逻辑,并且需信号控制。
module RegisterFile(
input clk,
input reset,
input WE, // 寄存器堆写使能,1为有效
input [4:0] WAddr,
input [31:0] WData,
input [4:0] RAddr1,
input [4:0] RAddr2,
output [31:0] RData1,
output [31:0] RData2
);
reg [31:0] registers [1:31]; // 31个32位寄存器,0号寄存器不可写,未在此定义
integer i;
// 读数据(组合逻辑)
assign RData1 = (RAddr1 == 0) ? 0 : registers[RAddr1];
assign RData2 = (RAddr2 == 0) ? 0 : registers[RAddr2];
// 写数据(时序逻辑,时钟下降沿写入)
always @(negedge clk or negedge reset) begin
if(reset == 0) begin
for(i = 1; i <= 31; i=i+1) begin
registers[i] <= 0;
end
end
else if(WE == 1 && WAddr != 0)
registers[WAddr] <= WData;
end
endmodule
ALU.v
运算器,一共有 14 种功能。
module ALU(
input [3:0] ALUControl,
input [31:0] A,
input [31:0] B,
output reg [31:0] result,
output zero, // 结果是否为0?是为1,否为0
output sign // 结果是否为负?是为1,否为0
);
assign zero = (result == 0) ? 1 : 0;
assign sign = result[31];
always @(ALUControl or A or B) begin
case(ALUControl)
`ALU_ADD: result = A + B;
`ALU_SUB: result = A - B;
`ALU_SLL: result = B << A;
`ALU_SRL: result = B >> A;
`ALU_OR: result = A | B;
`ALU_AND: result = A & B;
`ALU_SLTU: result = (A < B) ? 1 : 0; // 无符号比较
`ALU_SLT: result = ($signed(A) < $signed(B)) ? 1 : 0; // 带符号比较
`ALU_XOR: result = A ^ B;
`ALU_NOR: result = ~(A | B); // 或非
`ALU_MUL: result = A * B; // 乘法
`ALU_MOD: result = A % B; // 取模
`ALU_A: result = A; // A
`ALU_B: result = B; // B
default: result = 32'bz; // 默认输出高阻抗
endcase
end
endmodule
DataRAM.v
数据存储器 (DRAM)。读写都需要信号控制。
module DataRAM(
input clk,
input RD, // 读控制,1有效
input WR, // 写控制,1有效
input [31:0] addr,
input [31:0] DataIn,
output [31:0] DataOut // 读出32位数据
);
reg [7:0] RAM [0:63]; // 64个存储单元,每个存储单元为一个字节
/* 读,组合逻辑 */
assign DataOut[7:0] = (RD==1) ? RAM[addr+3] : 8'bz;
assign DataOut[15:8] = (RD==1) ? RAM[addr+2] : 8'bz;
assign DataOut[23:16] = (RD==1) ? RAM[addr+1] : 8'bz;
assign DataOut[31:24] = (RD==1) ? RAM[addr+0] : 8'bz;
/* 写,时序逻辑,时钟下降沿写入 */
always @(negedge clk) begin
if(WR == 1) begin
RAM[addr+0] <= DataIn[31:24];
RAM[addr+1] <= DataIn[23:16];
RAM[addr+2] <= DataIn[15:8];
RAM[addr+3] <= DataIn[7:0];
end
end
endmodule
阶段隔离寄存器
IR.v
IR 模块是 FETCH 到 DECODE 阶段的寄存器,它不仅负责锁存指令码,还负责根据指令类型,将指令拆分为指令执行所需要的各信号字段。无需使用的字段(无关信号)将被设为高阻抗,这可以降低无关信号的自由变化对观察仿真波形的干扰。
module IR(
input clk,
input reset,
input [31:0] in,
output reg [5:0] op,
output reg [4:0] rs,
output reg [4:0] rt,
output reg [4:0] rd,
output reg [4:0] shamt,
output reg [5:0] func,
output reg [15:0] imm,
output reg [25:0] target
);
reg [31:0] tmp_inst;
always @(negedge clk or negedge reset) begin
if (reset == 0) begin
op <= 6'bz;
rs <= 5'bz;
rt <= 5'bz;
rd <= 5'bz;
shamt <= 5'bz;
func <= 6'bz;
imm <= 16'bz;
target <= 26'bz;
end else begin
case(in[31:26])
`R_TYPE: begin
case(in[5:0])
`SLL, `SRL: tmp_inst = {in[31:26], 5'bz, in[20:0]};
default: tmp_inst = {in[31:11], 5'bz, in[5:0]};
endcase
{op, rs, rt, rd, shamt, func} <= tmp_inst[31:0];
imm <= 16'bz;
target <= 26'bz;
end
`J, `JAL: begin
{op, target} <= {in[31:26], in[25:0]};
rs <= 5'bz;
rt <= 5'bz;
rd <= 5'bz;
shamt <= 5'bz;
func <= 6'bz;
imm <= 16'bz;
end
`JR: begin
{op, rs} <= {in[31:26], in[25:21]};
rt <= 5'bz;
rd <= 5'bz;
shamt <= 5'bz;
func <= 6'bz;
imm <= 16'bz;
target <= 26'bz;
end
`HALT: begin
op <= in[31:26];
rs <= 5'bz;
rt <= 5'bz;
rd <= 5'bz;
shamt <= 5'bz;
func <= 6'bz;
imm <= 16'bz;
target <= 26'bz;
end
// I-type
default: begin
{op, rs, rt, imm} <= in[31:0];
rd <= 5'bz;
shamt <= 5'bz;
func <= 6'bz;
target <= 26'bz;
end
endcase
end
end
endmodule
DFF32.v
DFF32 (32位D触发器) 作为 DECODE_EXE.v, EXE_MEM.v, MEM_WB.v 共用的底层模块,它们每需要锁存一个数据,就实例化一个 DFF32 模块。
module DFF32(
input clk,
input reset,
input [31:0] in,
output reg [31:0] out
);
always @(posedge clk or negedge reset) begin
if(reset == 0) out <= 32'b0;
else out <= in;
end
endmodule
位数扩展器
位数扩展器有 EXT16T32, EXT5T32 两个模块,它的功能是,根据控制信号对数据进行符号扩展或零扩展。
这里以 EXT16T32 代码为例,EXT5T32 与之类似。
EXT16T32.v
module EXT16T32(
input ExtSel, // 0: 零扩展, 1: 符号扩展
input [15:0] original,
output reg [31:0] extended
);
always @(*) begin
extended[15:0] <= original; // 低16位保持不变
if(ExtSel == 0) extended[31:16] <= 16'b0; // 零扩展
else begin // 符号扩展
if(original[15] == 0) extended[31:16] <= 16'b0;
else extended[31:16] <= 16'hFFFF;
end
end
endmodule
多路选择器
有 MUX2X32, MUX4X5, MUX4X32 三种多路选择器,它的功能是根据控制信号,从多个数据中选择出一个数据并输出。
这里以 MUX4X32 代码为例。
MUX4X32.v
module MUX4X32(
input [1:0] select,
input [31:0] in0, in1, in2, in3,
output reg [31:0] out
);
always @(*) begin
case(select)
2'b00: out = in0;
2'b01: out = in1;
2'b10: out = in2;
2'b11: out = in3;
default: out = 32'b0;
endcase
end
endmodule
2. 仿真
仿真文件
CPU_sim_1.v
module CPU_sim_1( );
// input
reg clk;
reg reset;
// output
// basic, FETCH
wire [2:0] state; // 状态机状态
wire [31:0] PC, nextPC; // 当前PC地址,下一PC地址
wire [31:0] instruction; // 指令
wire [5:0] op;
wire [5:0] func;
// DECODE
wire [4:0] rs, rt, rd; // 寄存器地址,rt,rd和$31竞争RegWAddr
wire [31:0] Reg_RData1, Reg_RData2; // 寄存器数据
// EXE
wire [4:0] sa; // 移位量,与ID_RegRData1竞争ALU_A
wire [15:0] imm; // 立即数,与ID_RegRData2竞争ALU_B
wire [25:0] target;
wire [31:0] ALU_A, ALU_B; // ALU输入
wire [31:0] ALU_result; // ALU结果
// MEM
wire [31:0] RAM_DataOut; // 存储器数据输出,与EX_ALU_result和PC+4竞争RegWData
// WB
wire [4:0] Reg_WAddr; // 写回寄存器地址
wire [31:0] Reg_WData; // 写回寄存器数据
// 实例化CPU
MulticycleCPU uut (
.clk(clk),
.reset(reset),
.state(state),
.currentPCAddr(PC),
.nextPCAddr(nextPC),
.IF_instrution(instruction),
.op(op),
.func(func),
.rs(rs),
.rt(rt),
.rd(rd),
.shamt(sa),
.imm(imm),
.target(target),
.ID_RegRData1(Reg_RData1),
.ID_RegRData2(Reg_RData2),
.ALU_A(ALU_A),
.ALU_B(ALU_B),
.EX_ALU_result(ALU_result),
.MEM_RAMDataOut(RAM_DataOut),
.RegWAddr(Reg_WAddr),
.RegWData(Reg_WData)
);
always #50 clk = ~clk; // 时钟周期100ns
initial begin
clk = 1;
reset = 0;
#25;
reset = 1; // 开始仿真
#52000; // 52000ns后断点
$stop;
end
endmodule
各信号说明
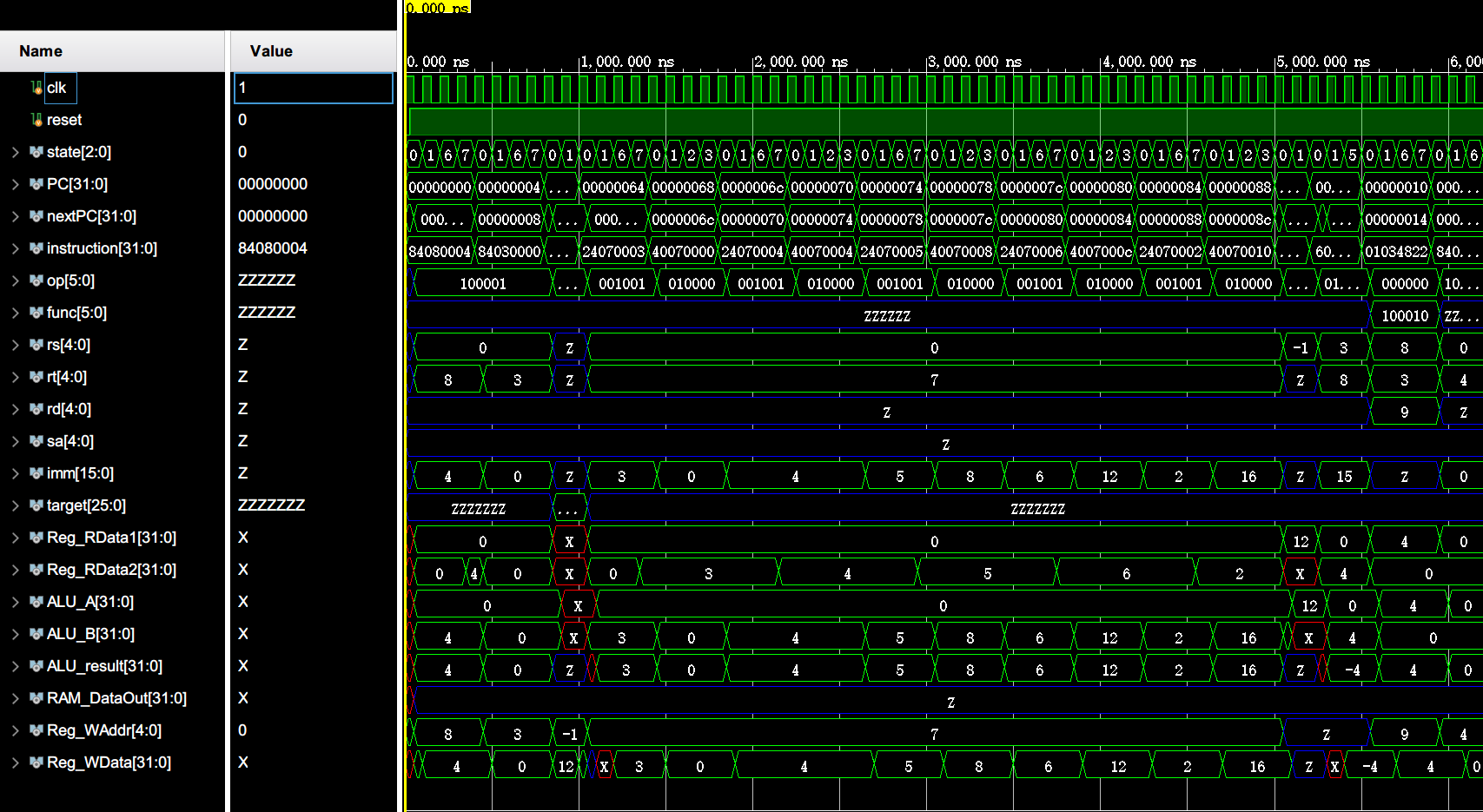
仿真波形图中信号含义
clk: 时钟,上升和下降沿均会触发相关电路变化
reset: 在下降沿复位
state: 状态机状态
PC, nextPC: 当前PC地址,下一PC地址
instruction: 指令
op, func: 操作码和功能码
rs, rt, rd: 寄存器地址,rt, rd和$31竞争RegWAddr
sa: 移位量,与Reg_RData1竞争ALU_A
imm: 立即数,与Reg_RData2竞争ALU_B
target: 目标地址
Reg_RData1, Reg_RData2: 寄存器数据
ALU_A, ALU_B: ALU输入
ALU_result: ALU结果
RAM_DataOut: 存储器数据输出,与 ALU_result 和 PC+4 竞争 Reg_WData
Reg_WAddr: 写回寄存器地址
Reg_WData: 写回寄存器数据
op,func,rs,rt,rd,sa,imm,target作为指令的一部分,它们只有在当前指令有相应的部分时才会产生有效输出,否则输出为高阻抗 Z。
对下面表格中“变化”一栏的说明
大括号 { } 的内容用来说明仿真波形中的信号变化,为了简化表示,我统一了表达方式,格式如下:
1. 信号名(信号值): 反映的寄存器编号
含义:当前信号的值,以及当前信号是反映某个寄存器的。
例子:
addiu $8, $0, 4
{ Reg_WData(4): $8 = Reg_RData1(0): $0 + imm(4) }
Reg_RData1为$0寄存器的值,其值为 0imm表示立即数,其值为 4Reg_WData表示需写回寄存器的值,写回寄存器位$8,写回值为 4.
2. MEM[ALU_result(地址值)] = 信号名(数据值)
含义:将当前信号的数据值存储到,由 ALU 计算出的地址值所表示的内存单元中。
例子:
sw $1, 4($5)
{ MEM[ALU_result(16)] = Reg_RData2(6) }
sw/lw指令的地址值一定是由 ALU 计算产生的,所以使用ALU_result反映读取/写入的地址值。Reg_RData2的值为 6 ($1的值,这里的: $1被省略),将存储到内存单元 16 中。
验证程序:冒泡排序
# ======================== 冒泡排序 ========================
# 汇编指令 -> 二进制机器码 (16进制)
# addiu $8, $0, 4 -> 100001 00000 01000 0000000000000100 (0x84080004)
# addiu $3, $0, 0 -> 100001 00000 00011 0000000000000000 (0x84030000)
# jal 0x00000064 -> 011110 00000000000000000000011001 (0x78000019)
# beq $3, $8, 15 -> 011000 00011 01000 0000000000001111 (0x6068000F)
# sub $9, $8, $3 -> 000000 01000 00011 01001 00000 100010 (0x01034822)
# addiu $4, $0, 0 -> 100001 00000 00100 0000000000000000 (0x84040000)
# addiu $5, $0, 0 -> 100001 00000 00101 0000000000000000 (0x84050000)
# beq $4, $9, 9 -> 011000 00100 01001 0000000000001001 (0x60890009)
# sll $5, $4, 2 -> 000000 00000 00100 0010100010000100 (0x00042884)
# lw $1, 0($5) -> 010001 00101 00001 0000000000000000 (0x44A10000)
# lw $2, 4($5) -> 010001 00101 00010 0000000000000100 (0x44A20004)
# slt $6, $2, $1 -> 000000 00010 00001 00110 00000 000010 (0x00413002)
# beq $6, $0, 2 -> 011000 00110 00000 0000000000000010 (0x60C00002)
# sw $1, 4($5) -> 010000 00101 00001 0000000000000100 (0x40A10004)
# sw $2, 0($5) -> 010000 00101 00010 0000000000000000 (0x40A20000)
# addiu $4, $4, 1 -> 100001 00100 00100 0000000000000001 (0x84840001)
# j 0x0000001c -> 011100 00000000000000000000000111 (0x70000007)
# addiu $3, $3, 1 -> 100001 00011 00011 0000000000000001 (0x84630001)
# j 0x0000000c -> 011100 00000000000000000000000011 (0x70000003)
# lw $7, 0($0) -> 010001 00000 00111 0000000000000000 (0x44070000)
# lw $7, 4($0) -> 010001 00000 00111 0000000000000100 (0x44070004)
# lw $7, 8($0) -> 010001 00000 00111 0000000000001000 (0x44070008)
# lw $7, 12($0) -> 010001 00000 00111 0000000000001100 (0x4407000c)
# lw $7, 16($0) -> 010001 00000 00111 0000000000010000 (0x44070010)
# halt -> 111111 00000000000000000000000000 (0xFC000000)
# ori $7, $0, 3 -> 001001 00000 00111 0000000000000011 (0x24070003)
# sw $7, 0($0) -> 010000 00000 00111 0000000000000000 (0x40070000)
# ori $7, $0, 4 -> 001001 00000 00111 0000000000000100 (0x24070004)
# sw $7, 4($0) -> 010000 00000 00111 0000000000000100 (0x40070004)
# ori $7, $0, 5 -> 001001 00000 00111 0000000000000101 (0x24070005)
# sw $7, 8($0) -> 010000 00000 00111 0000000000001000 (0x40070008)
# ori $7, $0, 6 -> 001001 00000 00111 0000000000000110 (0x24070006)
# sw $7, 12($0) -> 010000 00000 00111 0000000000001100 (0x4007000c)
# ori $7, $0, 2 -> 001001 00000 00111 0000000000000010 (0x24070002)
# sw $7, 16($0) -> 010000 00000 00111 0000000000010000 (0x40070010)
# jr $31 -> 011101 11111 000000000000000000000 (0x77E00000)
# ======================== 各寄存器功能 ========================
# $1 = array[addr]
# $2 = array[addr + 1]
# $3 = i
# $4 = j, j表示数组中的第j个元素(从0开始)
# $5 = addr = j << 2, 表示该元素在数组中的地址 ($4,$5必须一起变化)
# $6 = array[addr + 1] < array[addr] 时,$6 = 1
# $7 = 输入/输出数组临时寄存器
# $8 = n - 1
# $9 = n - i - 1
# $31 = 返回地址
# init(0x00):
addiu $8, $0, 4 # (0x00) $8 = n-1 = 4
addiu $3, $0, 0 # (0x04) i = 0
jal 0x00000064 # (0x08) 初始化数组, GOTO load_array
# outer_loop(0x0c):
# for (i = 0; i != n-1; i++)
beq $3, $8, 15 # (0x0c) if i == n-1, GOTO end_outer_loop
sub $9, $8, $3 # (0x10) $9 = n-i-1
addiu $4, $0, 0 # (0x14) j = 0
addiu $5, $0, 0 # (0x18) addr = 0
# inner_loop(0x1c):
# for (j = 0; j != n-i-1; j++)
beq $4, $9, 9 # (0x1c) if j == n-i-1, GOTO end_inner_loop
# get array elements
sll $5, $4, 2 # (0x20) addr = j << 2
lw $1, 0($5) # (0x24) $1 = array[addr]
lw $2, 4($5) # (0x28) $2 = array[addr + 1]
# compare
slt $6, $2, $1 # (0x2c) $6 = (array[addr+1] < array[addr]) ? 1 : 0
beq $6, $0, 2 # (0x30) if $6 == 0(不交换), GOTO no_swap
# swap
sw $1, 4($5) # (0x34) array[addr+1] = $1
sw $2, 0($5) # (0x38) array[addr] = $2
# no_swap(0x3c):
addiu $4, $4, 1 # (0x3c) j++
j 0x0000001c # (0x40) GOTO inner_loop
# end_inner_loop(0x44):
addiu $3, $3, 1 # (0x44) i++
j 0x0000000c # (0x48) GOTO outer_loop
# end_outer_loop(0x4c):
# 方便从仿真波形中观察排序后的数组
lw $7, 0($0) # (0x4c) $7 = array[0]
lw $7, 4($0) # (0x50) $7 = array[1]
lw $7, 8($0) # (0x54) $7 = array[2]
lw $7, 12($0) # (0x58) $7 = array[3]
lw $7, 16($0) # (0x5c) $7 = array[4]
halt # (0x60) 程序终止
# load_array(0x64):
ori $7, $0, 3 # (0x64)
sw $7, 0($0) # (0x68) array[0] = 3
ori $7, $0, 4 # (0x6c)
sw $7, 4($0) # (0x70) array[1] = 4
ori $7, $0, 5 # (0x74)
sw $7, 8($0) # (0x78) array[2] = 5
ori $7, $0, 6 # (0x7c)
sw $7, 12($0) # (0x80) array[3] = 6
ori $7, $0, 2 # (0x84)
sw $7, 16($0) # (0x88) array[4] = 2
jr $31 # (0x8c) 返回
array[5] = {3, 4, 5, 6, 2},冒泡排序后变成 array[5] = {2, 3, 4, 5, 6}
接下来开始仿真执行这段程序。
阶段一:初始化 (0 ~ 5200 ns)

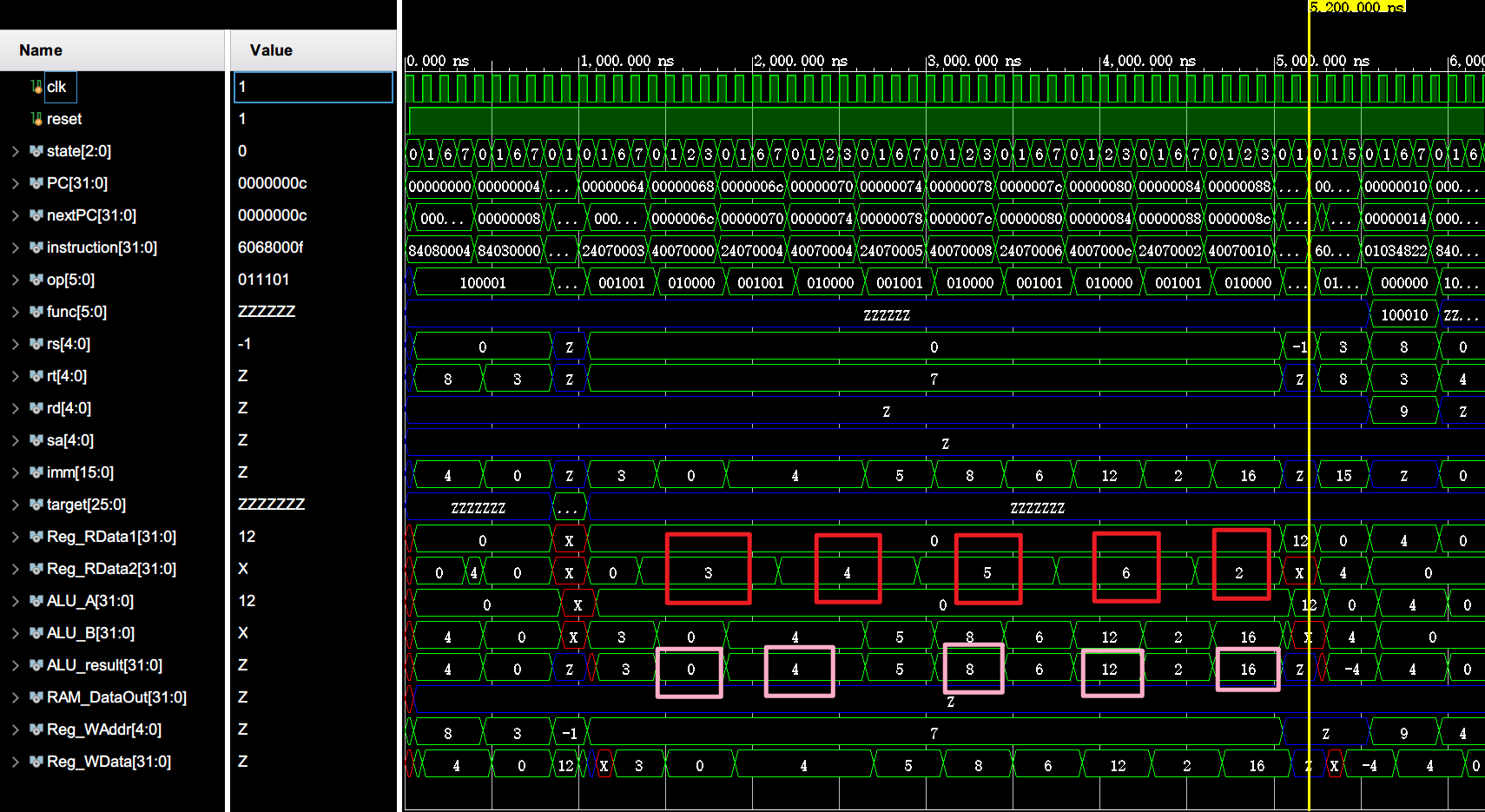
红框为数组元素,粉框为内存单元地址计算结果。
阶段二:排序 (5200 ~ 50800 ns)
外层循环开头段 (outer_loop) [PC: 0x0c ~ 0x18]
这里仅展示第一次进入 outer_loop 时的各项变化。

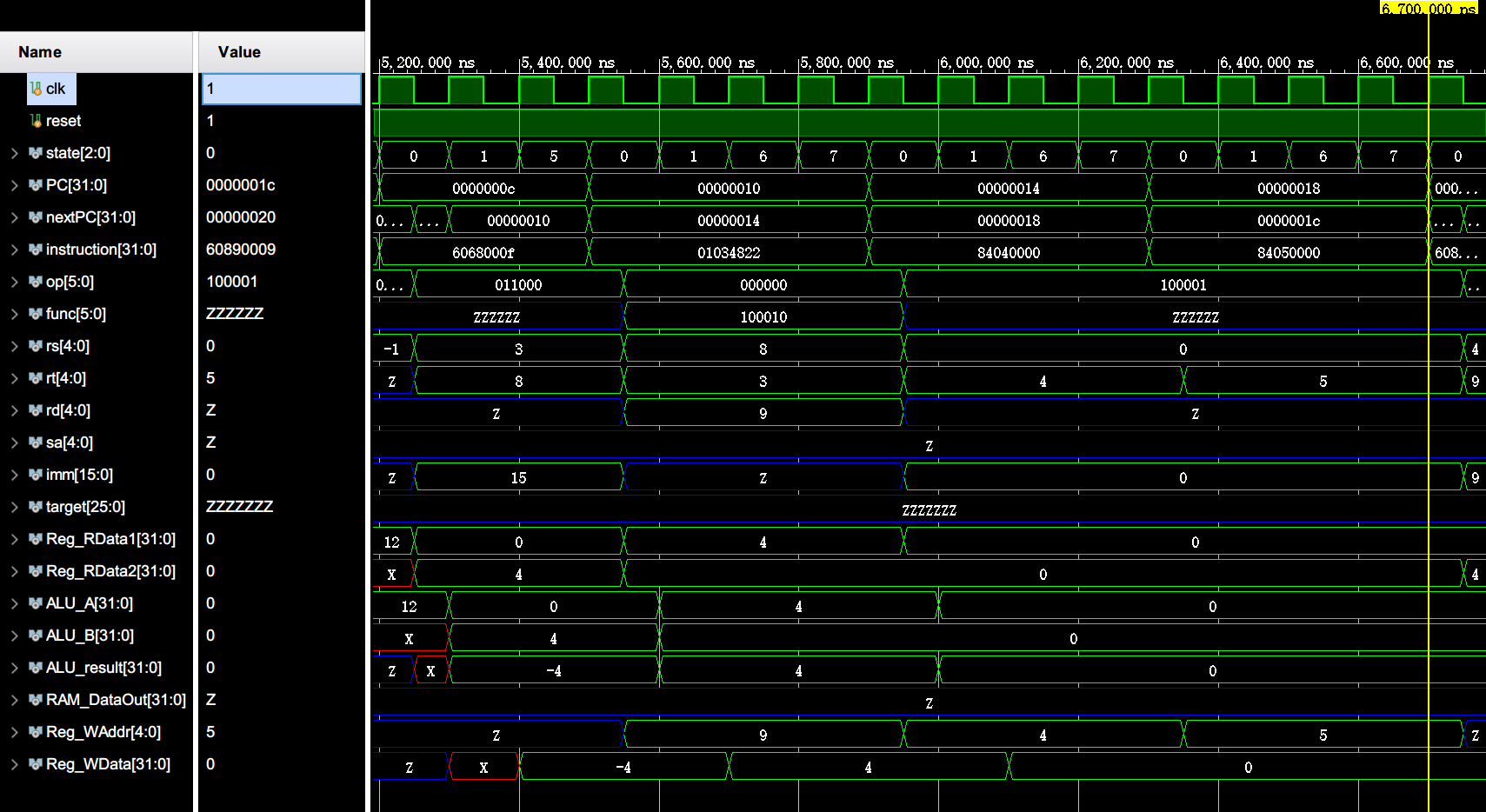
进入内层循环 (inner_loop) [PC: 0x1c ~ 0x40]
这里仅展示第一次进入 inner_loop 时的各项变化。
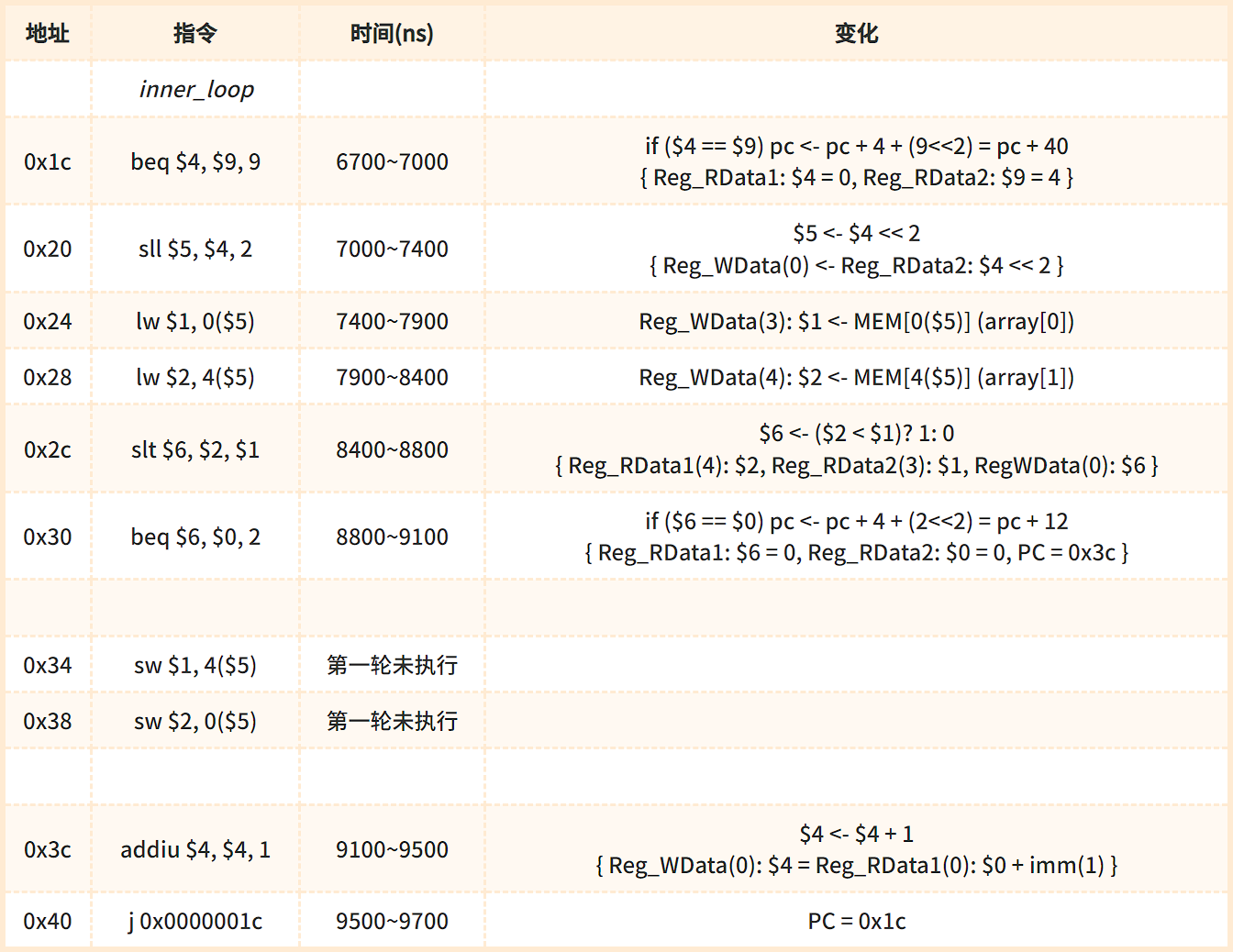
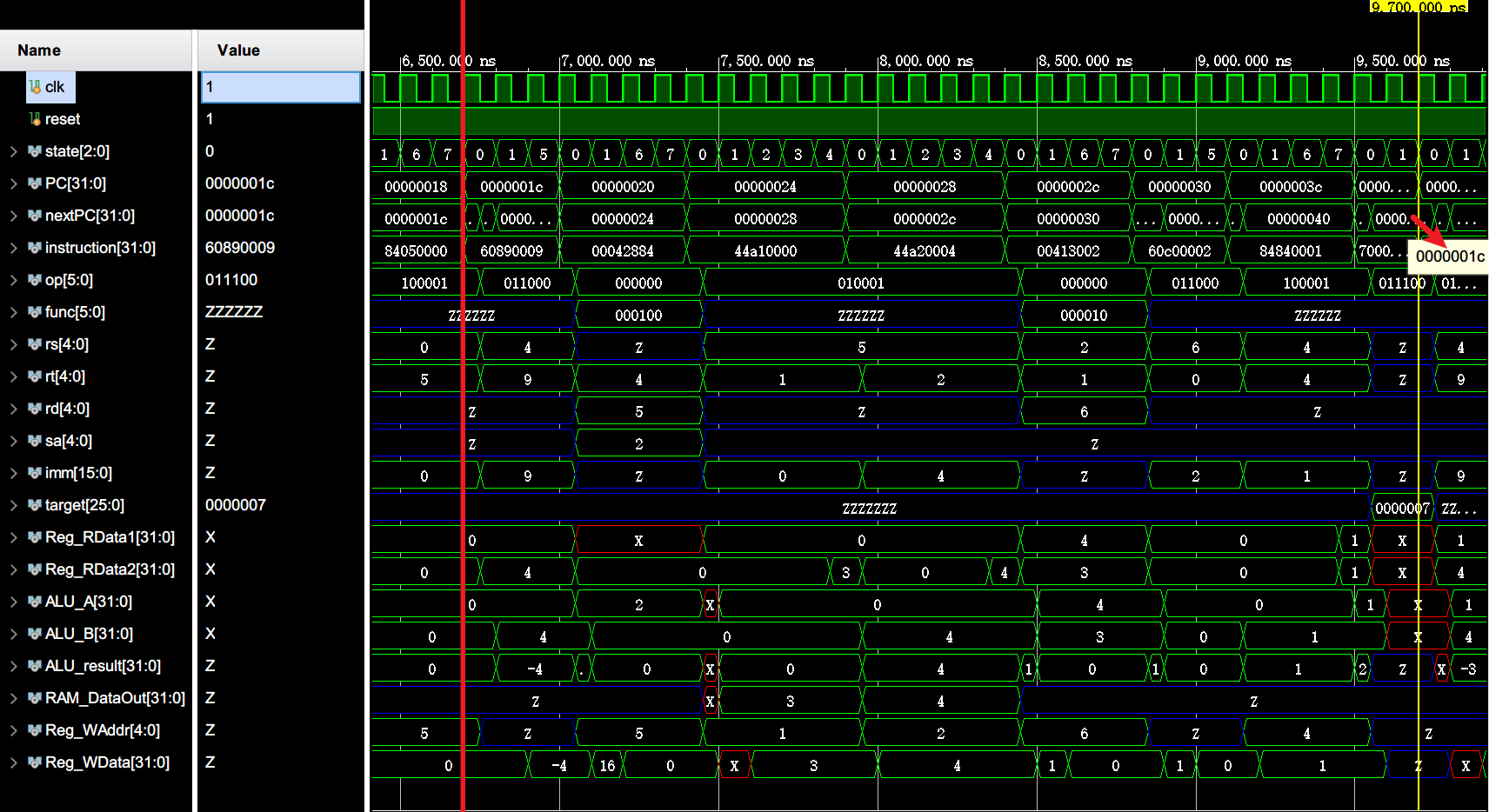
swap 执行
第一次执行swap段时如下表:

结果:存储单元中 {3, 4, 5, 6, 2} 变成了 {3, 4, 5, 2, 6}。
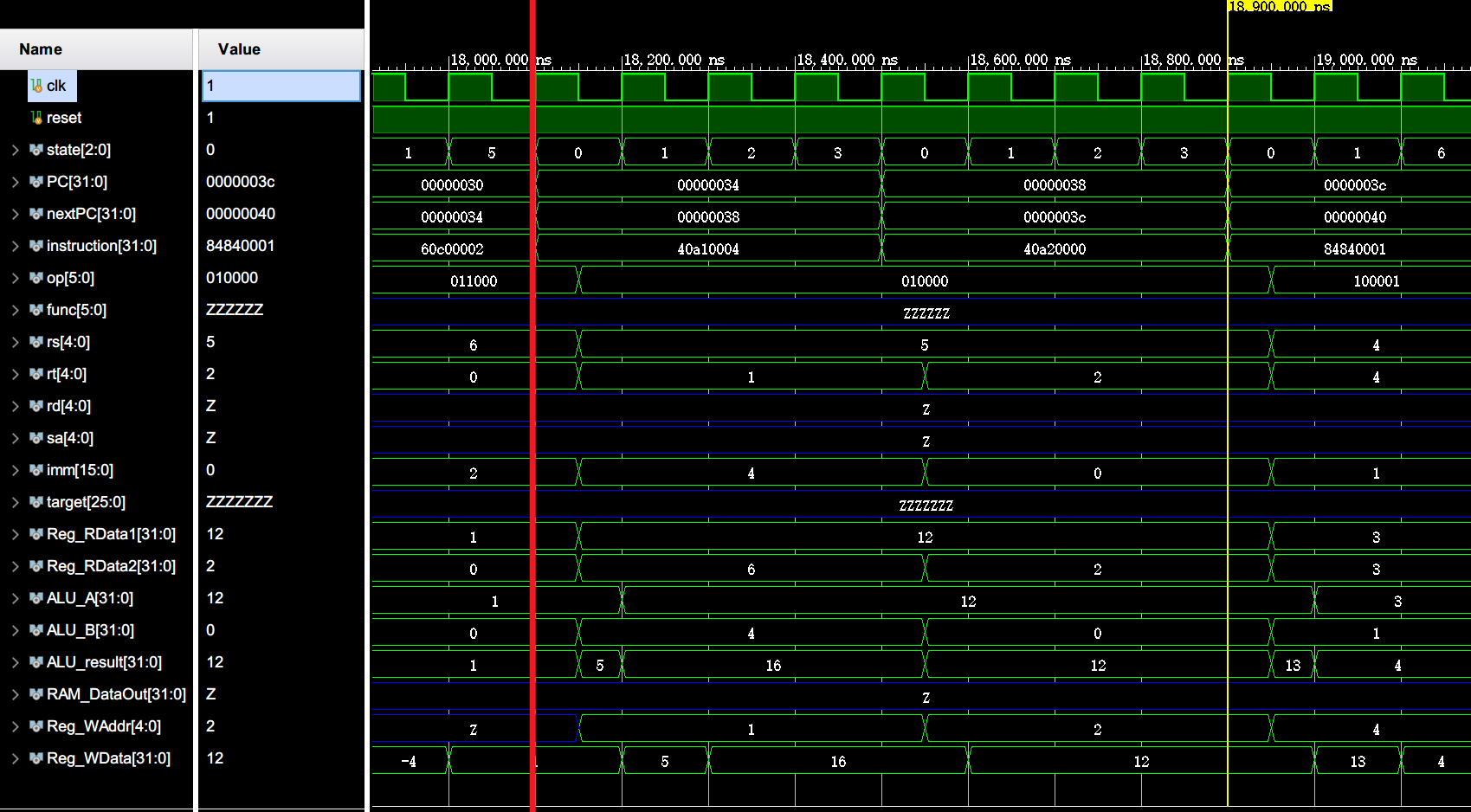
内层循环结束 (end_inner_loop)
这里仅展示第一次进入 end_inner_loop 时的各项变化。
第一轮内层循环结束时(内层循环达到了跳出条件),由 0x1c 处的 beq 指令跳转到内层循环结束段 end_inner_loop (0x44)。

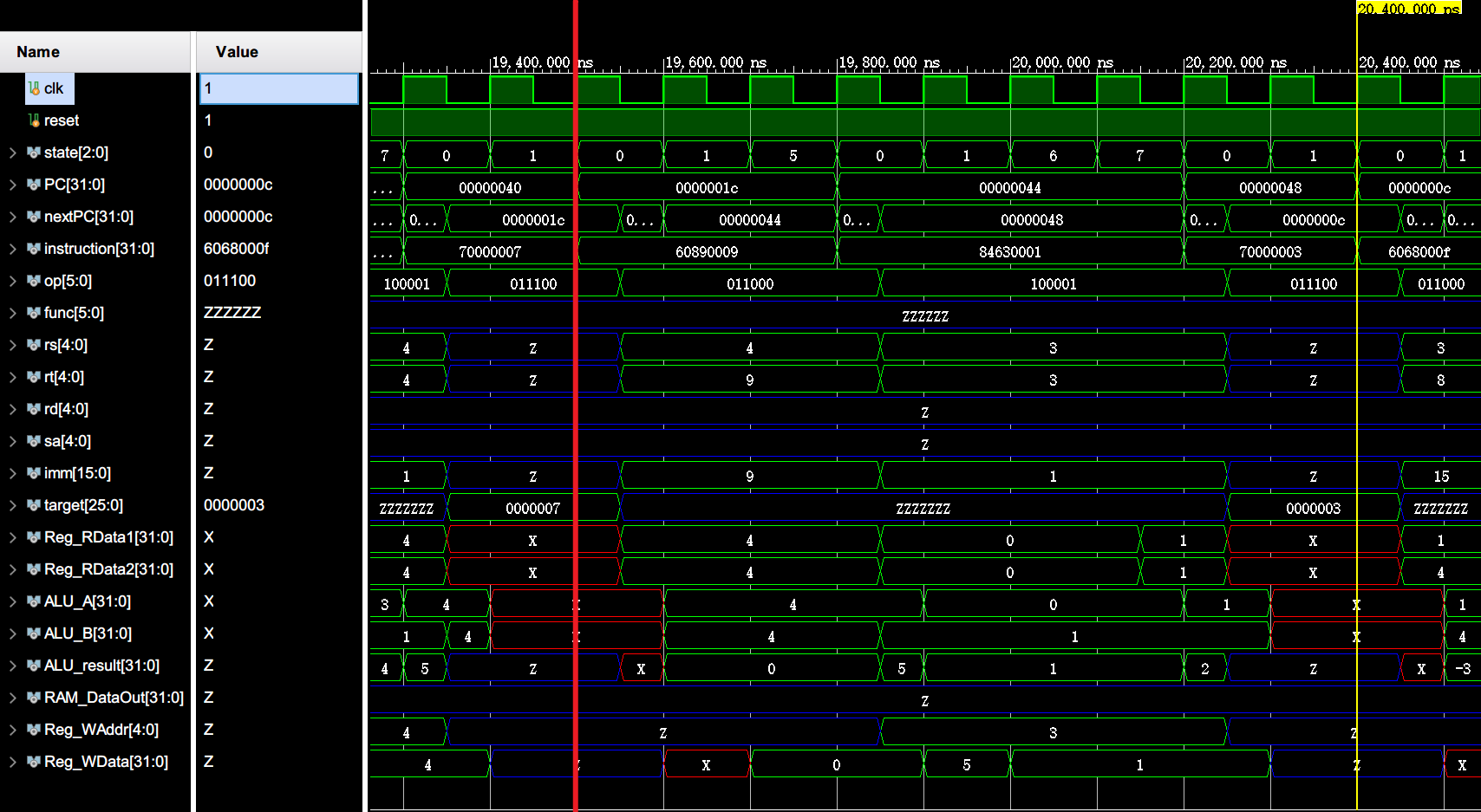
外层循环结束 (end_outer_loop)
外层循环结束时(外层循环达到了跳出条件),由 0x0c 处的 beq 指令跳转到外层循环结束段 end_outer_loop (0x4c),也就是程序的末尾。
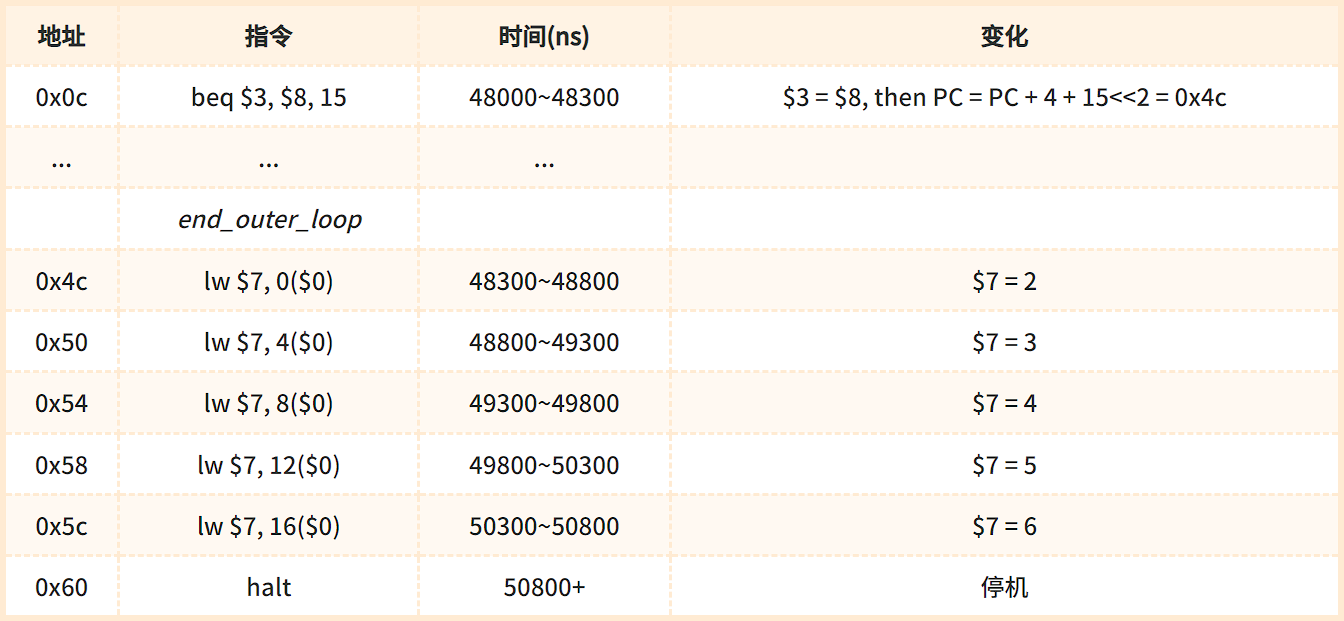
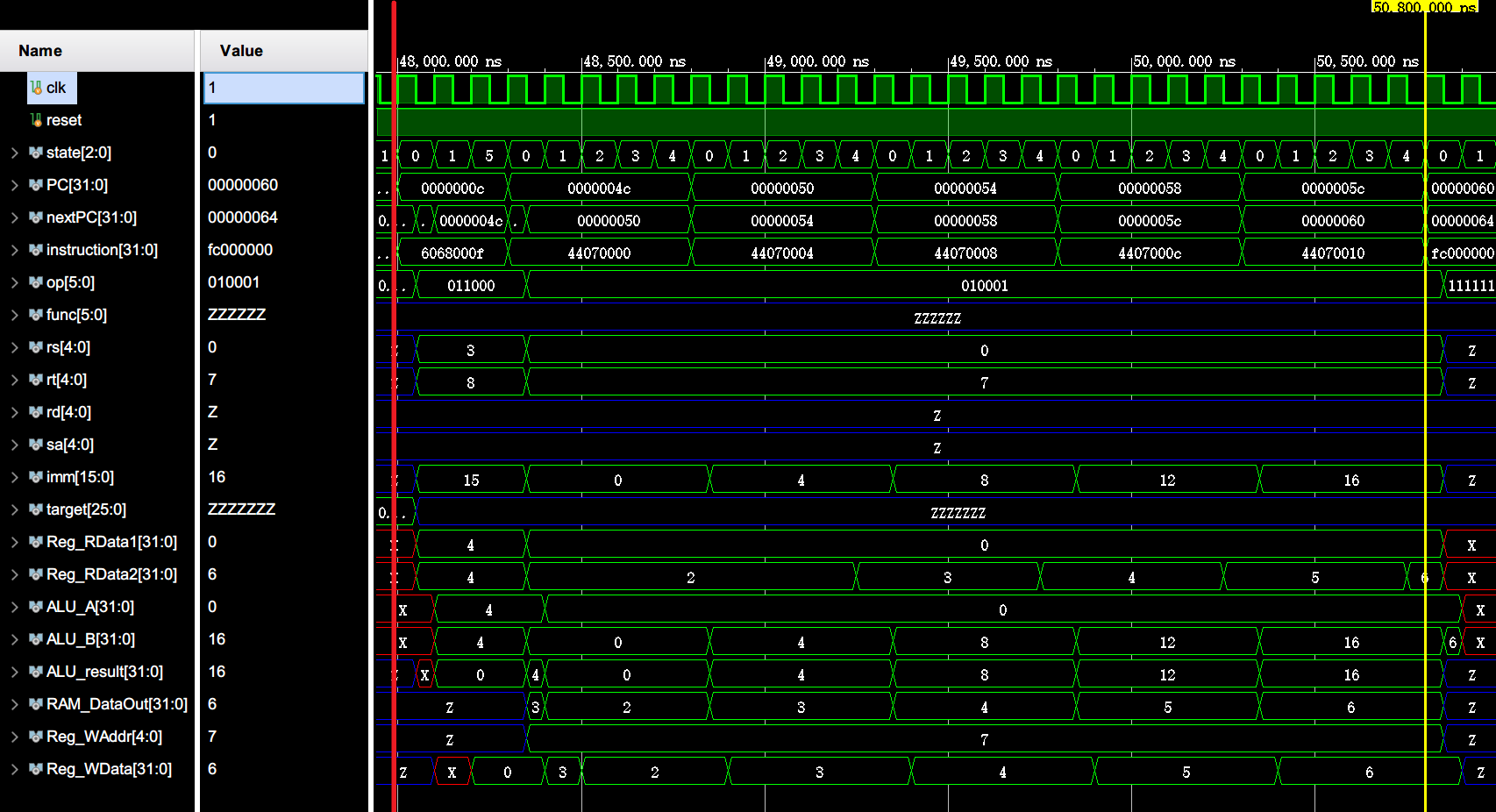
总时间表 (0 ~ 50800+ ns)
三、心得体会
在本次多周期CPU的实验过程中,我学到了许多关于计算机体系结构和数字电路设计的知识。这个实验不仅加深了我对MIPS指令集和Verilog硬件描述语言的理解,还让我在解决实际问题的过程中锻炼了自己的动手能力和逻辑思维能力。以下是我在这个实验中一些关键步骤和心得体会的总结。
多周期CPU设计是一种高效的计算机体系结构,它通过将指令执行过程分为多个周期,从而提高了硬件资源的利用率。实验的目标是设计并实现一个基于MIPS指令集的多周期CPU,并通过编写汇编代码对其进行测试和验证。
遇到的问题
在完成硬件设计后,由于手写二进制机器码过于繁琐,所以我根据我的指令集编写了一个汇编器,让我能够自动、便捷地将汇编代码转换为二进制机器码,也提高了对Python语言的熟练度。通过实验,我加深了对MIPS指令集的理解,并学会了如何使用汇编语言实现一些基本算法。
在此过程中,我遇到了许多问题,例如如何正确处理指令的跳转和分支(地址拼接不仅是CPU层面的,在转换成二进制代码时也需要通过汇编器进行特殊处理),如何使用立即数进行计算等。通过不断调试和优化汇编代码,我逐渐解决了这些问题。
之后,还遇到了许多意想不到的问题。例如,在设计指令ROM时,由于ROM的每个存储单元只有1个字节,而每条指令占4个字节,因此需要将每条指令拆分为4个字节并逐字节存储。这让我更加深刻地理解了计算机存储和指令执行的原理。
状态机和控制单元的设计是十分精妙的,首先我用宏定义避免了这些模块代码中会大量出现的二进制文本,在对状态转换关系和对控制信号的处理时,我花了大量时间去分析各个指令的执行流程和规律,汇总出状态转换图和指令与控制信号的对应关系表。这些使得我最后的状态机和控制单元代码精炼了许多。
感悟
通过本次实验,我深刻体会到设计和实现一个多周期CPU所需的知识和技能是多么广泛和复杂。从硬件设计到软件编写,再到问题调试和解决,每一步都需要扎实的理论基础和实践经验。本次实验使我对计算机体系结构有了更深入的理解,并让我的Verilog编程能力得到了显著提升。在实验中遇到的各种问题,让我学会了如何查找资料、分析问题和解决问题。这些经验对我未来的学习和工作都有很大的帮助。